课题组在顶级期刊IEEE Transactions on Cybernetics 发表学术论文《SpaSSA: Superpixelwise Adaptive SSA for Unsupervised Spatial-Spectral Feature Extraction in Hyperspectral Image》。该期刊为计算机科学与工程技术1区TOP,JCR分区Q1,中科院1区TOP,最新影响因子为11.448。
论文针对高光谱影像的地物尺度复杂问题,基于传统的奇异谱分析(SSA)方法,提出了一种新型的超像素自适应SSA(SpaSSA),可以自适应地提取高光谱影像丰富的空间地物特征,取得了与深度学习方法相媲美的性能。
研究背景
在高光谱影像(hyperspectral image, HSI)分类中,复杂的地物尺度、波段冗余和空谱域噪声会严重影响数据的分析,因此有效地特征提取是至关重要的。
近些年来,一种新型的基于时间序列分析的技术,奇异谱分析(Singular Spectral Analysis, SSA)已被成功地应用于HSI的特征提取,其中常规1D-SSA作用于光谱域而2D-SSA用于空间域处理。然而,该方法存在对处理窗口尺寸敏感、计算复杂度高、无法提取联合光谱空间特征等缺点。方法为了解决这些问题,本文提出了一种新型的超像素自适应SSA(Superpixelwise adaptive SSA, SpaSSA)算法,有效提取不同地物的局部空间特征。
研究方法
本文提出的SpaSSA方法的流程图如图1所示,主要包括三个部分:(i) 超像素分割映射;(ii) SpaSSA;(iii) 分类。详情如下。
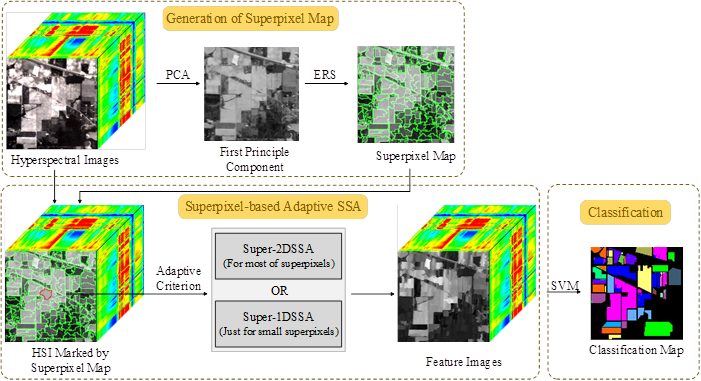
图1 提出的SpaSSA方法流程图。
在SpaSSA中,针对不同大小的超像素进行自适应处理,即大部分的超像素都使用Super-2DSSA来处理,而剩余的较小的超像素使用Super-1DSSA来处理,处理方式如图2~3所示。
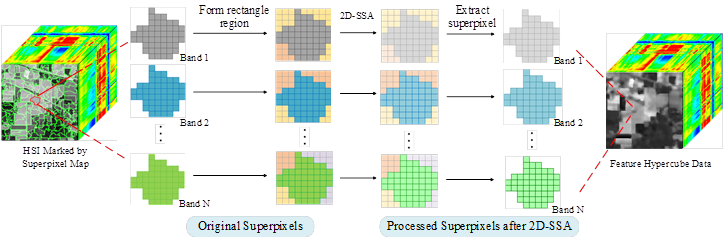
图2 Super-2DSSA方法流程图。
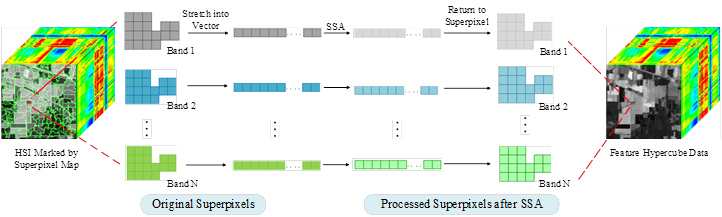
图3 Super-1DSSA方法流程图。
结果结论
(1)在分类精度上,提出的SpaSSA在绝大多数类别都取得最高的分类精度,优于传统的SSA、2DSSA,并且其自适应的方式要好于单独的Super-1DSSA和Super-2DSSA。
表1 Indian Pines数据集的分类精度(%)(10%训练样本)
Class | Train | Test | SVM | SSA (L=10) | Super-1DSSA (L1-D =10) | 2DSSA (5×5) | 2DSSA (10×10) | Super-2DSSA (3×3) | SpaSSA |
Alfalfa | 5 | 41 | 14.63 | 73.17 | 97.56 | 70.73 | 78.05 | 60.98 | 85.37 |
Corn-notill | 143 | 1285 | 75.33 | 81.87 | 91.05 | 92.45 | 91.67 | 91.52 | 96.11 |
Corn-mintill | 83 | 747 | 66.67 | 77.38 | 92.10 | 94.11 | 96.52 | 92.10 | 96.79 |
Corn | 24 | 213 | 46.01 | 70.42 | 76.06 | 95.31 | 98.59 | 87.79 | 99.53 |
Grass-pasture | 49 | 434 | 85.71 | 94.47 | 99.08 | 97.70 | 98.16 | 96.77 | 97.70 |
Grass-trees | 73 | 657 | 92.39 | 92.54 | 99.09 | 98.63 | 97.26 | 98.17 | 99.24 |
Grass-pasture-mowed | 3 | 25 | 68.00 | 80.00 | 72.00 | 88.00 | 96.00 | 80.00 | 100.0 |
Hay-windrowed | 48 | 430 | 99.07 | 99.77 | 99.77 | 98.37 | 98.60 | 98.84 | 100.0 |
Oats | 2 | 18 | 33.33 | 55.56 | 94.44 | 100.0 | 72.22 | 88.89 | 100.0 |
Soybean-notill | 98 | 874 | 75.06 | 84.21 | 95.31 | 92.91 | 93.59 | 90.85 | 94.97 |
Soybean-mintill | 246 | 2209 | 84.56 | 84.93 | 97.92 | 96.42 | 97.28 | 94.21 | 98.87 |
Soybean-clean | 60 | 533 | 61.54 | 74.30 | 85.18 | 92.87 | 90.99 | 84.43 | 97.56 |
Wheat | 21 | 184 | 91.85 | 90.76 | 99.46 | 98.91 | 98.37 | 97.28 | 99.46 |
Woods | 127 | 1138 | 93.76 | 91.39 | 99.12 | 98.77 | 98.95 | 98.77 | 99.38 |
Buildings | 39 | 347 | 57.35 | 49.57 | 93.08 | 98.85 | 98.85 | 95.97 | 99.71 |
Stone-Steel-Towers | 10 | 83 | 79.52 | 85.54 | 96.39 | 100.0 | 96.39 | 100.0 | 100.0 |
OA | 79.75 | 84.02 | 95.13 | 95.76 | 96.00 | 93.79 | 97.97 | ||
AA | 70.30 | 80.37 | 92.97 | 94.63 | 93.84 | 91.03 | 97.79 | ||
kappa×100 | 76.79 | 81.78 | 94.44 | 95.16 | 95.43 | 92.92 | 97.69 | ||
(2)SpaSSA方法可以得到更加平滑的分类图,消除了对比算法中存在的分类“椒盐噪声”和分类斑块的问题,在不同地物的边界处具有良好的区分性。
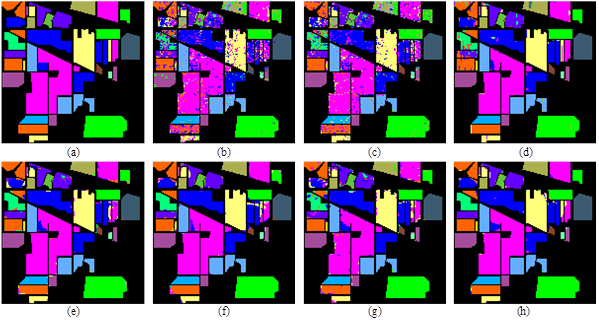
图4 Indian Pines数据集分类图。(a)真值图;(b)SVM;(c)SSA;(d)Super-1DSSA;(e)2DSSA(5*5);(f) 2DSSA(10*10);(g)Super-2DSSA;(h)SpaSSA。
(3)在运行时间上,Super-1DSSA比SSA节省了较多的计算时间。Super-2DSSA中超像素的数量增加了2DSSA的处理次数,SpaSSA比Super-2DSSA需要更多的时间,进一步提高SpaSSA的效率还有待进一步研究。
表2 不同对比算法的运行时间对比
Method | Parameters | Time(s) | ||
Indian Pines | Pavia University | Salinas | ||
SSA | 10 | 8.59 | 112.80 | 39.33 |
Super-1DSSA | 10 | 4.20 | 79.52 | 34.44 |
2D-SSA | 5×5 | 8.25 | 40.50 | 44.11 |
10×10 | 14.41 | 80.69 | 85.25 | |
Super-2DSSA | 3×3 | 18.51 | 195.82 | 154.57 |
SpaSSA | Optimal parameter | 27.96 | 229.02 | 215.85 |
(4)提出的SpaSSA方法与PCA进一步结合(SpaSSA-PCA),旨在实现更有效的光谱空间特征提取。实验结果证明,该方法可以与当前先进的流形学习、深度学习方法相媲美。
表3 Indian Pines数据集不同先进方法的分类精度(%)(约10%训练样本)
| Original Data of Full Dimension (200). | Reduced Dimension of Data (20). | ||||||||
3DCNN | SSRN | DBMA | LAJSR | SpaSSA | PCA | RLMR | Super-PCA | 2DSSA-PCA | SpaSSA-PCA | |
OA | 90.38 | 98.22 | 98.65 | 96.71 | 98.00 | 72.49 | 84.30 | 95.91 | 96.03 | 98.34 |
AA | 88.39 | 98.08 | 96.98 | 95.09 | 98.52 | 67.67 | 86.63 | 96.05 | 95.48 | 98.45 |
kappa | 0.890 | 0.980 | 0.976 | 0.949 | 0.978 | 0.686 | 0.821 | 0.951 | 0.953 | 0.982 |
论文全文链接
https://ieeexplore.ieee.org/document/9533174